논문리뷰 ·
논문리뷰: From Blind Spots to Gains: Diagnostic‑Driven Iterative Training for Large Multimodal Models
한 줄 요약
모델의 약점을 진단→맞춤 데이터 생성→강화학습으로 반복 보완하는 DPE 루프가 LMM 성능을 지속적으로 개선한다.
메타
- 제목: From Blind Spots to Gains: Diagnostic‑Driven Iterative Training for Large Multimodal Models
- 저자: Hongrui Jia 외
- 연도: 2026
- 링크: https://arxiv.org/abs/2602.22859
문제 정의
대형 멀티모달 모델의 학습은 정적 데이터/고정 레시피에 의존해, 실제 약점(Blind Spot)을 진단하고 맞춤 보완하기 어렵다. 단순한 자기생성 데이터는 품질과 타깃성이 부족하다.
핵심 기여
- DPE(Diagnostic‑driven Progressive Evolution) 루프 제안
- 약점 진단을 기반으로 데이터 생성과 RL을 반복하는 학습 구조
- 다중 에이전트로 데이터 품질·다양성을 확보
- 11개 벤치마크에서 지속적 성능 향상 보고
방법/구성 (논문 목차 흐름)
- Diagnosis: 실패를 약점 유형으로 분류
- Data Evolution: 약점 중심 데이터 생성/정제
- RL Reinforcement: 약점 데이터로 재학습
- 반복 루프 형성
에이전트 구성
- Planner Agent: 목표/계획 수립
- Image Selector Agent: 시각 입력 선정
- Question Generator Agent: 평가 쿼리 생성
- Validation Agent: 품질/정답 검증
실험/결과 (논문 요약 기반)
- Qwen3‑VL‑8B‑Instruct / Qwen2.5‑VL‑7B‑Instruct에서 11개 벤치마크 전반 향상
- 반복 루프가 continual gains를 제공한다고 보고
한계/의문점
- 진단 정확도가 낮을 경우 편향 루프 형성 위험
- 에이전트/도구 기반 데이터 생성의 비용·스케일이 병목
내 생각
- 교육의 “오답 진단→맞춤 학습”과 유사한 구조라 직관적이다.
- 향후에는 진단 신뢰도와 성능 향상의 상관관계가 명확히 제시되어야 설득력이 커질 듯하다.
Figures (핵심 이미지)
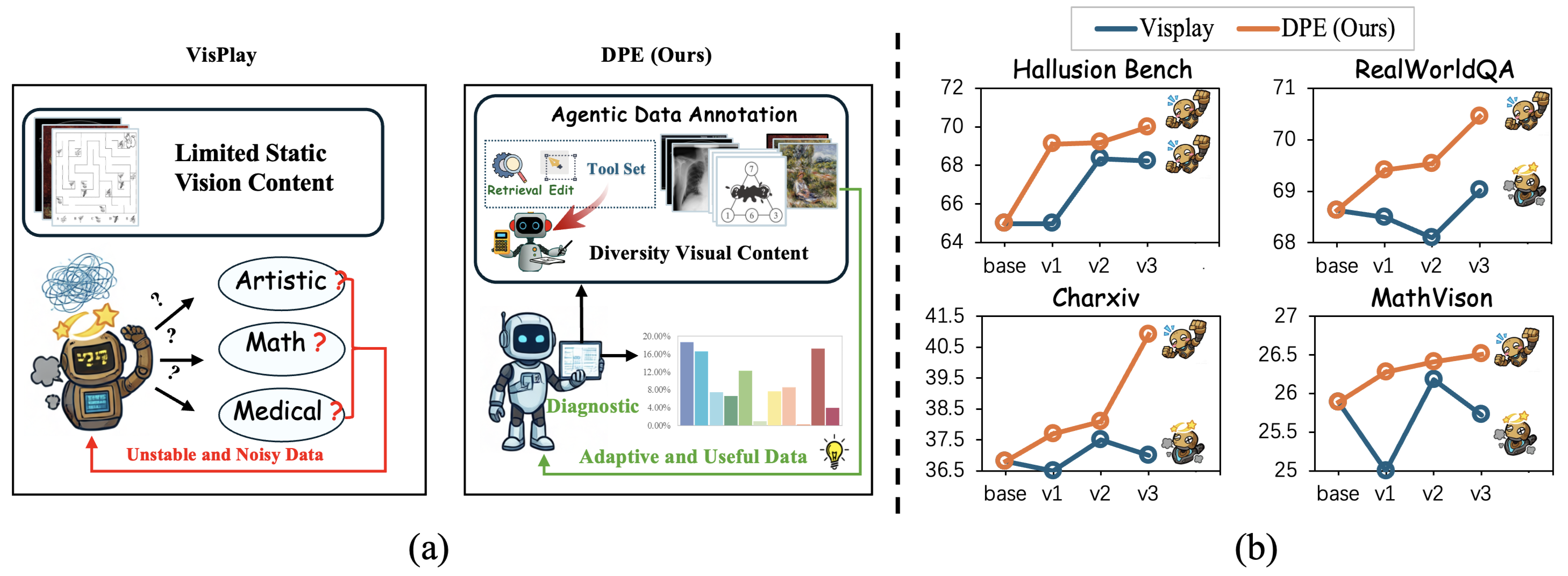 Figure 1: Limits of prior self-evolution frameworks
Figure 1: Limits of prior self-evolution frameworks
 Figure 2: Overview of the DPE framework
Figure 2: Overview of the DPE framework
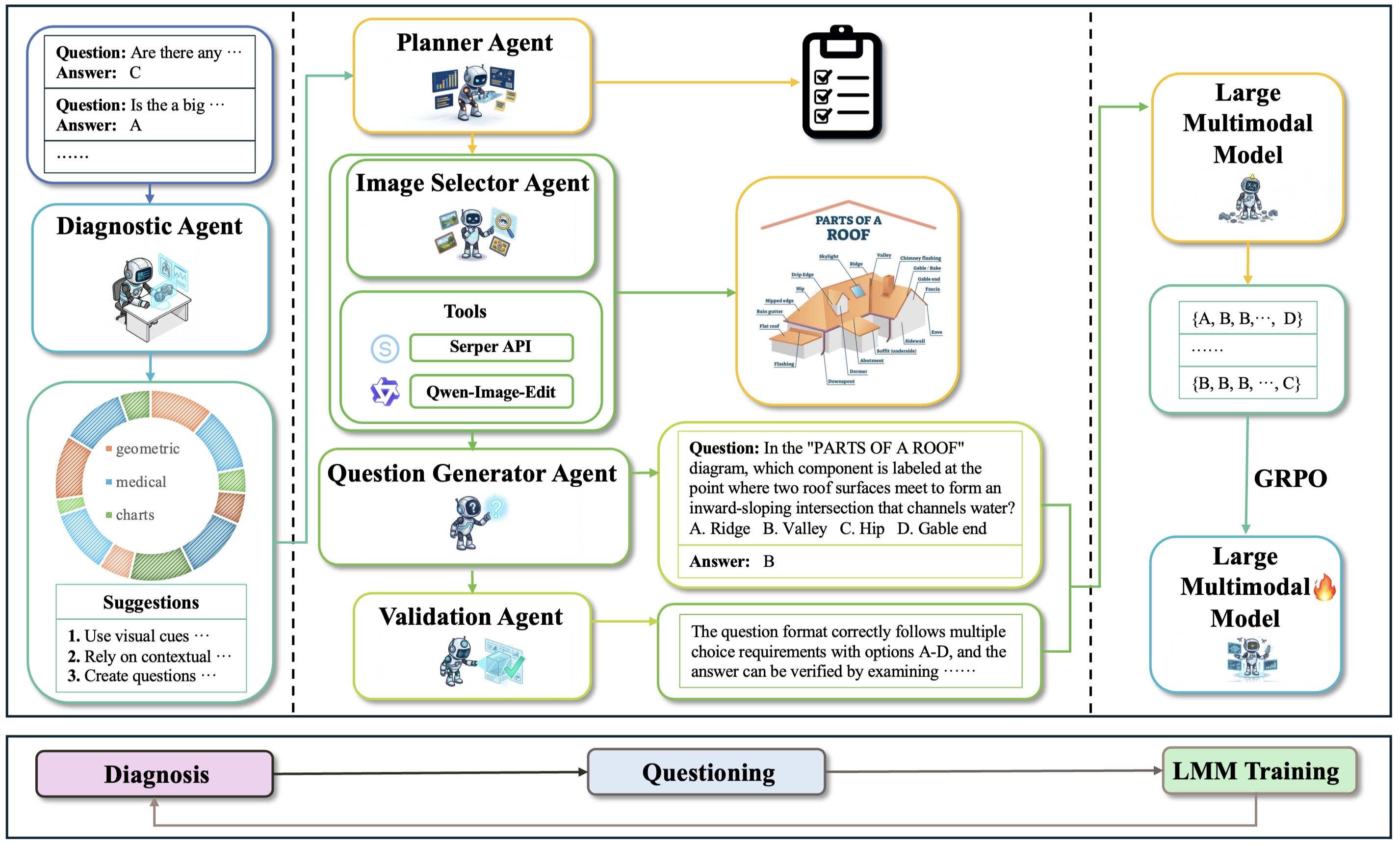 Figure 5: UMAP visualization of data diversity
Figure 5: UMAP visualization of data diversity